Lesson 5: Selecting Parts of a Web Page
Suppose we want, from a wikipedia page, only the content, that too as pure text without any html tags and the like. First, we need to examine the Web page through a special tool, for instance the Web Developer toolbar that is available as a plugin for Firefox. We click on a paragraph in the content part, and ask the web developer toolbar for information about this element. This is what it shows us.
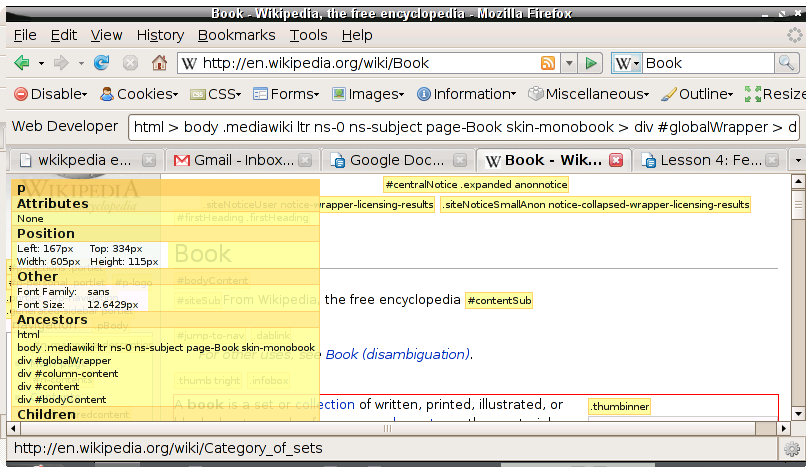
Important to note, that the immediate ancestor of the content portion is a division with the id "bodyContent". That is all we need to know, to solve this problem. The code:
require 'rubygems'
require 'hpricot'
lw='Book'
doc = open(lw+".html") { |f| Hpricot(f) }
bc=doc.search('#bodyContent')
ds=bc/:p
ds.each {|pa| puts pa.inner_text }
It is assumed that you have actually run the code in Lesson 4, so that a file Book.html exists in the current folder. We use open with Hpricot to put the contents of Book.html into a variable called doc.
The next line bc=doc.search('#bodyContent') puts into bc only the portion within the div that has the id "bodyContent". The line ds=bc/:p slices up bc, taking out all the paragraphs, and puts them into an array called ds. The last line simply invokes the inner_text function on each item in the ds array, and prints it out. Who thought slicing and dicing web pages could be so much fun?